在數字化時代,大數據已成為驅動商業洞察、科學研究和智能決策的核心燃料。原始數據如同未經雕琢的玉石,其價值的釋放依賴于一套嚴謹、系統的處理流程。本文旨在詳細拆解大數據處理的全過程,從最初的零起點到最終的結論驗證,為讀者勾勒出一條清晰的技術與實踐路線圖。
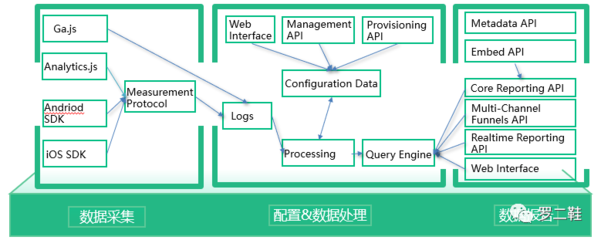
第一階段:數據采集與獲取
一切始于數據。數據來源極其多樣,包括但不限于:
1. 業務系統日志:如網站點擊流、應用程序日志。
2. 傳感器與物聯網設備:實時產生的海量物理世界數據。
3. 公開數據集與第三方數據:用于補充和豐富分析維度。
4. 社交媒體與公開網絡:通過爬蟲等技術獲取的非結構化數據。
關鍵挑戰在于確保數據采集的實時性、完整性和合法性,并設計高效的數據攝取管道,將數據從源頭平穩地導入存儲或處理平臺。
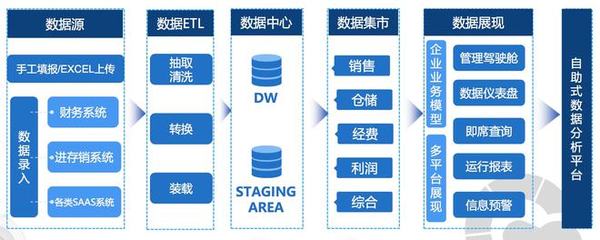
第二階段:數據存儲與管理
采集到的數據需要被妥善存儲和管理。根據數據結構和訪問模式,存儲方案通常分為:
- 大數據存儲系統:如Hadoop HDFS(用于分布式文件存儲)、NoSQL數據庫(如HBase、Cassandra,適用于非結構化或半結構化數據)和云對象存儲(如AWS S3)。
- 數據湖/數據倉庫:數據湖存儲原始、未經處理的數據;數據倉庫則存儲清洗、轉換后的結構化數據,服務于分析查詢。現代架構常采用湖倉一體模式。
管理的核心是元數據管理、數據目錄和數據安全策略,確保數據可發現、可理解、可信任且受保護。
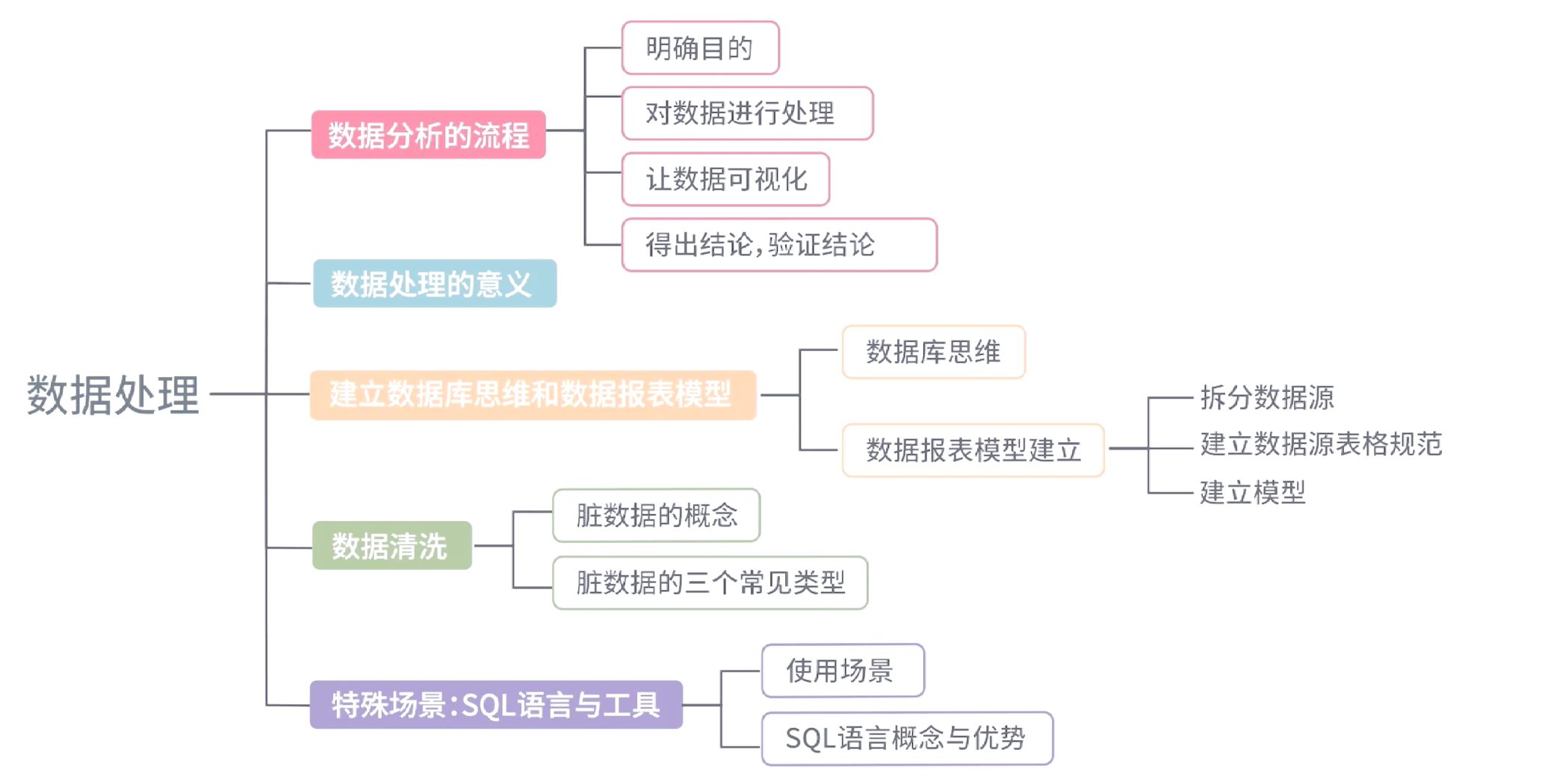
第三階段:數據預處理與清洗
這是提升數據質量的關鍵步驟,常被稱為“數據打磨”。主要任務包括:
- 數據清洗:處理缺失值、異常值、重復記錄和格式不一致問題。
- 數據轉換:進行標準化、歸一化、離散化等操作,使數據適應分析模型。
- 數據集成與融合:將來自不同源的數據進行關聯和合并,形成統一視圖。
此階段耗費大量精力,但“垃圾進,垃圾出”,高質量的數據是后續所有分析可靠性的基石。
第四階段:數據計算與分析
在此階段,數據被轉化為信息和洞察。根據處理時效性,可分為:
- 批處理:對靜態數據集進行離線、高吞吐量的計算,常用框架如Apache Spark、Flink(批模式)。適用于不追求實時性的歷史數據分析、報表生成。
- 流處理:對連續不斷的數據流進行實時或近實時計算,框架如Apache Flink、Storm、Kafka Streams。適用于監控、實時推薦、欺詐檢測等場景。
分析手段涵蓋描述性分析(發生了什么)、診斷性分析(為何發生)、預測性分析(將會發生什么)和規范性分析(應該采取什么行動),涉及統計分析、機器學習、數據挖掘等多種技術。
第五階段:數據可視化與探索
分析結果需要通過直觀的方式呈現,以輔助人類理解。數據可視化工具(如Tableau、Power BI、Superset)將復雜的數字和關系轉化為圖表、儀表盤和故事線。交互式數據探索允許分析師通過下鉆、篩選等操作,從不同角度和粒度動態探查數據,發現潛在的模式和異常。
第六階段:建模、應用與部署
當分析目標指向預測或自動化決策時,需要構建和訓練模型(如機器學習模型)。流程包括:特征工程、模型選擇、訓練、評估與調優。一個成功的模型需要被部署到生產環境,集成到業務應用程序或服務中,以API、嵌入式模塊等形式提供持續的服務,實現數據價值的最終產品化。
第七階段:結論驗證與流程閉環
這是確保整個數據處理流程科學、可靠的最后防線,也是常常被忽視的一環。
- 結果可重復性:確保在相同的數據和流程下,能夠復現分析結論。
- 統計顯著性檢驗:對于從數據中得出的模式或差異,使用統計方法檢驗其是否顯著,而非隨機波動。
- 業務合理性驗證:數據結論必須與業務邏輯和領域知識交叉驗證。一個統計上顯著的發現,如果業務上無法解釋,可能需要重新審視數據或方法。
- A/B測試與反饋循環:對于基于數據結論提出的策略或模型變更,通過A/B測試等方法在受控環境下驗證其實際效果。將線上真實反饋數據重新收集,形成閉環,用于監控模型性能、發現數據漂移,并觸發模型的迭代更新或流程的優化。
****
大數據處理并非一蹴而就的單一動作,而是一個從物理世界到數字世界,再從數字洞察反饋回物理實踐的循環迭代工程。每個階段都環環相扣,缺一不可。從零開始的數據采集到嚴謹的結論驗證,這條完整鏈路不僅關乎技術實現,更體現了數據驅動的科學方法論:以數據為始,以驗證為終,在持續的循環中逼近真相、創造價值。掌握全流程,方能真正駕馭大數據的力量。